Spark vs Hadoop: Melyik a legjobb Big Data Framework?
Ez a blogbejegyzés az apache spark vs hadoop szóról szól. Ez ötletet ad arról, hogy melyik a megfelelő Big Data keretrendszer, amelyet különféle esetekben kell választani.

Ez a blogbejegyzés az apache spark vs hadoop szóról szól. Ez ötletet ad arról, hogy melyik a megfelelő Big Data keretrendszer, amelyet különféle esetekben kell választani.
Ez a blog segít megérteni, hogyan kell telepíteni és beállítani az sbteclipse bővítményt, lépésről lépésre leírva a Scala alkalmazás futtatását az Eclipse IDE programban.
Ez a blogbejegyzés elmagyarázza, miért kell elkezdenie az Apache Spark használatát Hadoop után, és miért tehet csodákat a karrierje során a Spark megtanulása a hadoop elsajátítása után!
Ez az Apache Drill oktatóanyag minden szükséges információt megad Önnek az Apache Drill lekérdező motor használatának megkezdéséhez, a Hadoop használatához, a Big Data & Apache Sparkhoz.
Ez a Spark Hadoop blog mindent elárul, amit tudnia kell az Apache Spark combByKey-ről. A combybyKey módszerrel keresse meg az egy tanulóra eső átlagos pontszámot.
Az Apache Falcon egy új adatkezelési platform a Hadoop ökoszisztémához, amely leegyszerűsíti a takarmány-feldolgozást és a hadoop-fürtök feed-kezelését. Tudja meg, hogyan kell beállítani.
Ez az Apache Spark blog részletesen ismerteti a Spark akkumulátorokat. Ismerje meg a Spark akkumulátor használatát példákkal. A szikra akkumulátorok olyanok, mint a Hadoop Mapreduce számlálók.
Tudjon meg mindent az Apache Flinkről és a Flink-fürt beállításáról ebben a blogban. A Flink támogatja a valós idejű és kötegelt feldolgozást, és a Big Data Analytics számára kötelező a Big Data technológia.
Ez a blogbejegyzés az elosztott gyorsítótárat tárgyalja sugárzott változókkal, és elkezdi a nagy értékek hatékony elosztását a Spark programozásban.
A Cloudera CCA és CCP tanúsítványai felváltották a CCDH és a CCSHB vizsgákat. Ez a blog mindent elárul, amit tudnia kell az új képesítésekről.
Ez a blogbejegyzés az állapotszerű átalakításokat tárgyalja a Spark Streaming segítségével. Tudjon meg mindent a kötegelt adatok nyomon követéséről az állapotfüggő D-adatfolyamok használatával.
Ez a blogbejegyzés a Spark Streaming állapotát érintő átalakításokat tárgyalja. Tudjon meg mindent a Hadoop Spark karrier összesített nyomon követéséről és fejlesztéséről.
A Hadoop & Big Data technológiák forradalmasítják az egészségügyi elemzéseket. Ez a nagy adat az egészségügyi blogban azt tárgyalja, hogy a nagy adatelemzés hogyan képes feljavítani az orvosi ellátást.
Ez a Hadoop Streamingről szóló blogbejegyzés lépésről-lépésre segít megtanulni Hadoop MapReduce programot írni Python-ban nagy mennyiségű Big Data feldolgozásához.
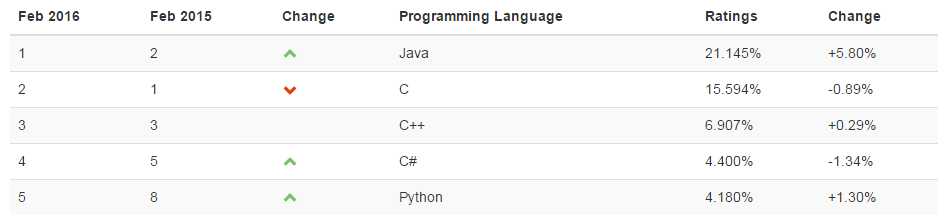
Ez a Big Data Tutorial blog teljes áttekintést nyújt a Big Data-ról, annak jellemzőiről, alkalmazásairól, valamint a Big Data kihívásairól.
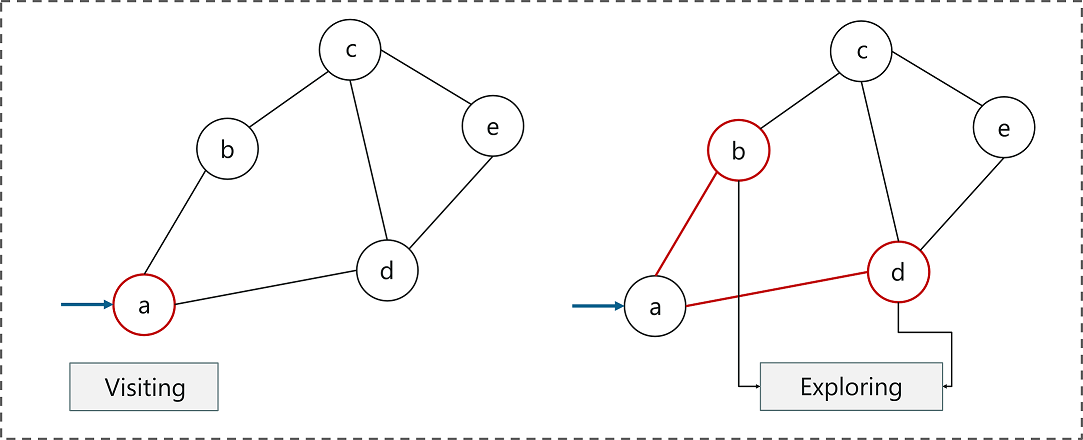
Ez a HDFS oktatóblog segít megérteni a HDFS vagy a Hadoop elosztott fájlrendszert és annak szolgáltatásait. Röviden meg fogja vizsgálni annak fő elemeit is.
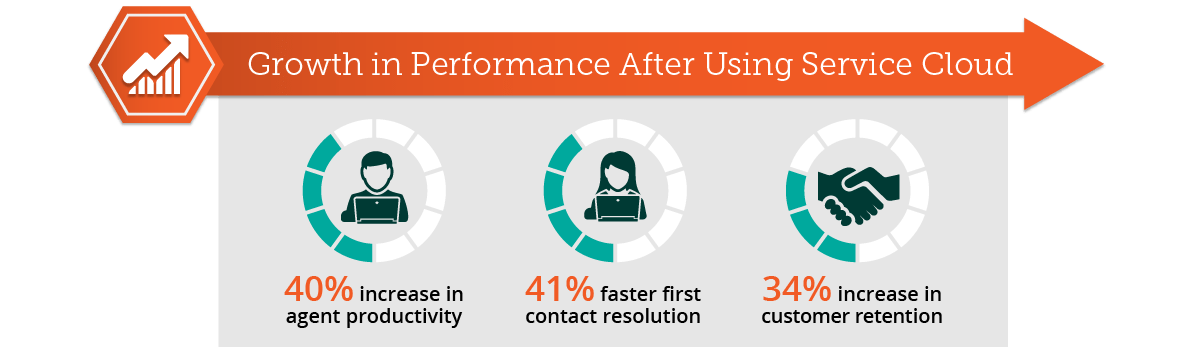
Ebben a Splunk oktatóanyagban ismerje meg a Splunk vs. ELK és a Sumo Logic közötti különbségeket, és határozza meg, hogy ezek közül az eszközök közül melyik felel meg Önnek a legjobban.
Ebben a Splunk használati eset blogban meg fogja érteni, hogy a Domino's Pizza hogyan használta fel a Splunkot a fogyasztói viselkedésről szóló betekintés megszerzéséhez. És megfogalmazza üzleti stratégiáikat.
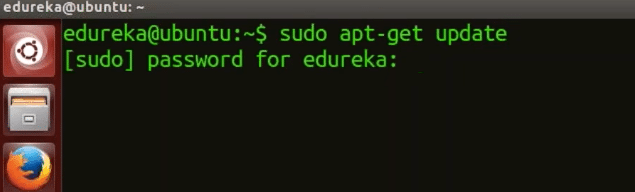
Ez az oktatóanyag lépésről lépésre ismerteti a Hadoop-fürt telepítését és konfigurálását egyetlen csomóponton. A Hadoop összes telepítési lépése a CentOS gépre vonatkozik.
Ez a blog a HDFS különféle parancsairól szól, például az fsck, copyFromLocal, expunge, cat stb., Amelyek a Hadoop fájlrendszer kezelésére szolgálnak.